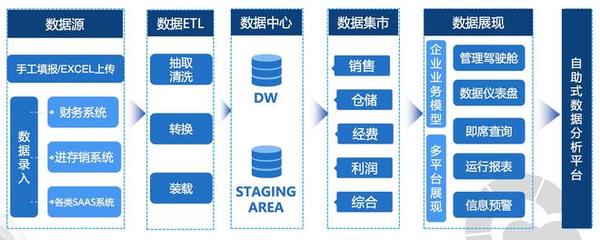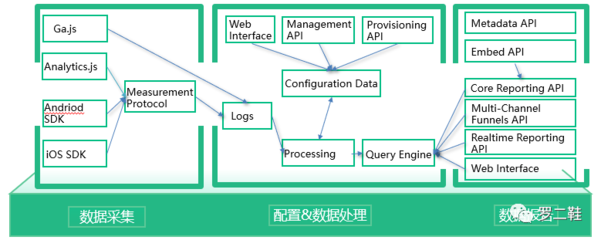
在當今數據驅動的時代,高效處理海量數據已成為企業(yè)決策與業(yè)務創(chuàng)新的核心需求。眾多大數據處理工具應運而生,而Presto作為一款開源的分布式SQL查詢引擎,憑借其卓越的性能和靈活的架構,在數據處理領域占據了重要地位。本文將簡要介紹Presto的核心概念、架構特點及其在大數據生態(tài)系統(tǒng)中的應用價值。
一、Presto的核心定位
Presto最初由Facebook開發(fā),旨在解決其內部大規(guī)模數據分析的性能瓶頸。它并非傳統(tǒng)的數據庫,而是一個專為交互式分析查詢設計的引擎。其核心優(yōu)勢在于能夠對多種數據源(如HDFS、Hive、Cassandra、MySQL等)進行聯(lián)邦查詢,用戶可以使用標準的SQL語法,跨源聯(lián)合分析存儲在異構系統(tǒng)中的數據,無需進行復雜的數據遷移或轉換。
二、架構與工作原理
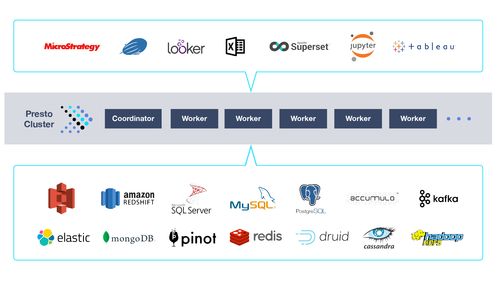
Presto采用主從(Master-Slave)架構,主要由以下兩個核心組件構成:
- 協(xié)調者(Coordinator):作為主節(jié)點,負責接收客戶端查詢請求、解析SQL語句、生成并優(yōu)化執(zhí)行計劃,并將任務分發(fā)給工作節(jié)點。它還負責管理所有工作節(jié)點的狀態(tài)并協(xié)調查詢的執(zhí)行過程。
- 工作節(jié)點(Worker):作為從節(jié)點,負責具體執(zhí)行協(xié)調者分配的任務,即處理數據塊并進行實際的計算。多個工作節(jié)點并行工作,共同完成一個查詢任務。
Presto的執(zhí)行引擎采用了獨特的“內存中”并行處理模型。查詢被分解成多個階段(Stage),每個階段又包含多個任務(Task),這些任務在不同工作節(jié)點上并行執(zhí)行,數據通過流水線在任務間流動,最大限度地減少了磁盤I/O,從而實現了極快的查詢速度,尤其適合交互式分析場景。
三、關鍵特性與優(yōu)勢
- 高性能與低延遲:通過內存計算、流水線執(zhí)行和動態(tài)編譯等優(yōu)化技術,Presto能夠在秒級甚至亞秒級完成對TB級數據集的查詢。
- 聯(lián)邦查詢能力:支持連接多個外部數據源進行關聯(lián)查詢,實現了數據的虛擬化集成,打破了數據孤島。
- 標準SQL支持:兼容ANSI SQL,降低了數據分析師的學習和使用門檻。
- 彈性擴展:架構無狀態(tài),可以輕松通過增加工作節(jié)點來水平擴展集群,以應對不斷增長的數據量和查詢負載。
- 與生態(tài)系統(tǒng)無縫集成:與Hive Metastore兼容良好,可以方便地查詢Hive表;同時支持連接Kafka、Redis等多種數據系統(tǒng)。
四、典型應用場景
Presto廣泛應用于交互式數據倉庫查詢、即席分析(Ad-hoc Analysis)、多源數據聯(lián)合報表以及數據探索等場景。例如,分析師可以直接使用SQL對存儲在HDFS上的歷史數據與實時流入Kafka的日志數據進行關聯(lián)分析,快速獲得業(yè)務洞察。
五、與展望
作為大數據處理棧中的重要一環(huán),Presto以其速度、靈活性和易用性,成為了企業(yè)構建實時數據分析平臺的優(yōu)選引擎之一。隨著云原生技術的發(fā)展,Presto也在持續(xù)演進,如由Presto原核心團隊創(chuàng)建的Trino項目(原PrestoSQL),正進一步推動其社區(qū)生態(tài)的繁榮。隨著數據量的持續(xù)爆炸式增長和實時性要求的不斷提高,Presto及其衍生技術將在數據處理與分析領域發(fā)揮更加關鍵的作用。